
Dimensional Modeling

A few articles ago, we delved into data storage. In this article, we will discuss data warehousing using dimensional modeling principles. Three of the most popular products to use for the creation of a data warehouse are: Snowflake, which is a fully managed columnar database; Microsoft Azure Synapse, which is a fully managed columnar database based on SQL Server; and Amazon Redshift, which is a fully managed columnar database based on PostgreSQL. Another option, which this article will focus on, is to create your own data warehouse, using star schema design principles, within a relational database.
Typically, data warehousing products like Snowflake, Synapse and Redshift are significantly more expensive than row-based relational database products. This cost difference can lead to the decision to build a data mart or warehouse in your existing operational database. In that case, it is important to research star and/or snowflake schema design principles, which are based on dimensional modeling, proposed by Ralph Kimball.
Assuming that you decide to use your existing relational database to build out a warehouse, the core parts of your data warehouse are fact and dimension tables. Fact tables are for data that changes frequently (events) while dimension tables are for slowly changing data (things). Let’s use a simple digital health example to help clarify things. In our example, we have the following tables in our operational database:
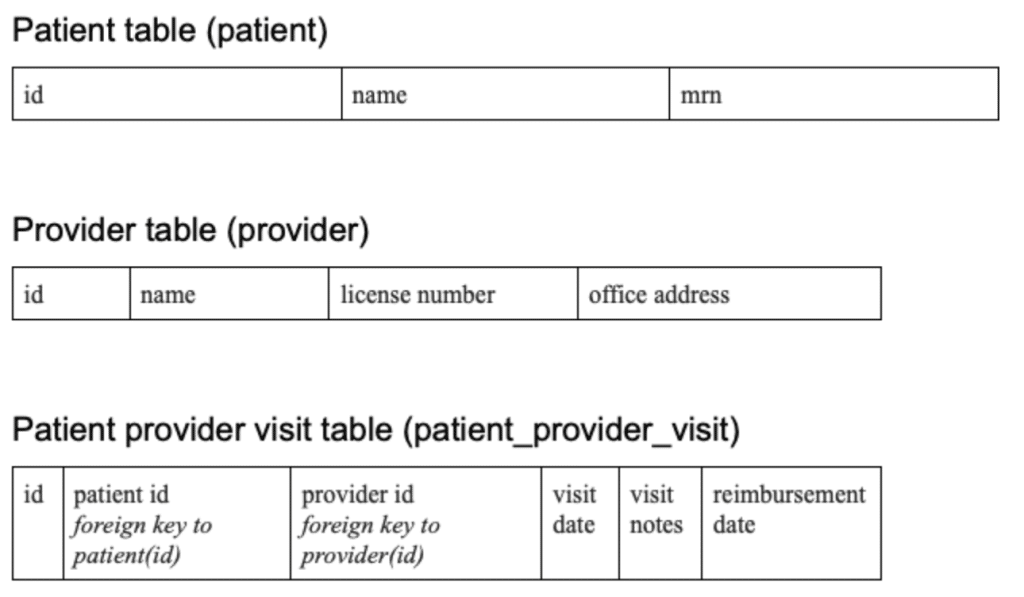
We would expect to have less provider records than patient records and less patient records than patient provider visit records.
Also, adding a reimbursement date column to the patient provider visit table would probably not be the best design, since it contains data that would only be known well after the actual visit. It is in the table above for demonstration purposes, which will become clear when we get to the data warehouse table design below.
If we wanted to make this data available for analysis, moving the operational records to our data warehouse would be required. This is typically done either periodically, say daily, or via a data drip.
A star schema design for our example could consist of the following tables:
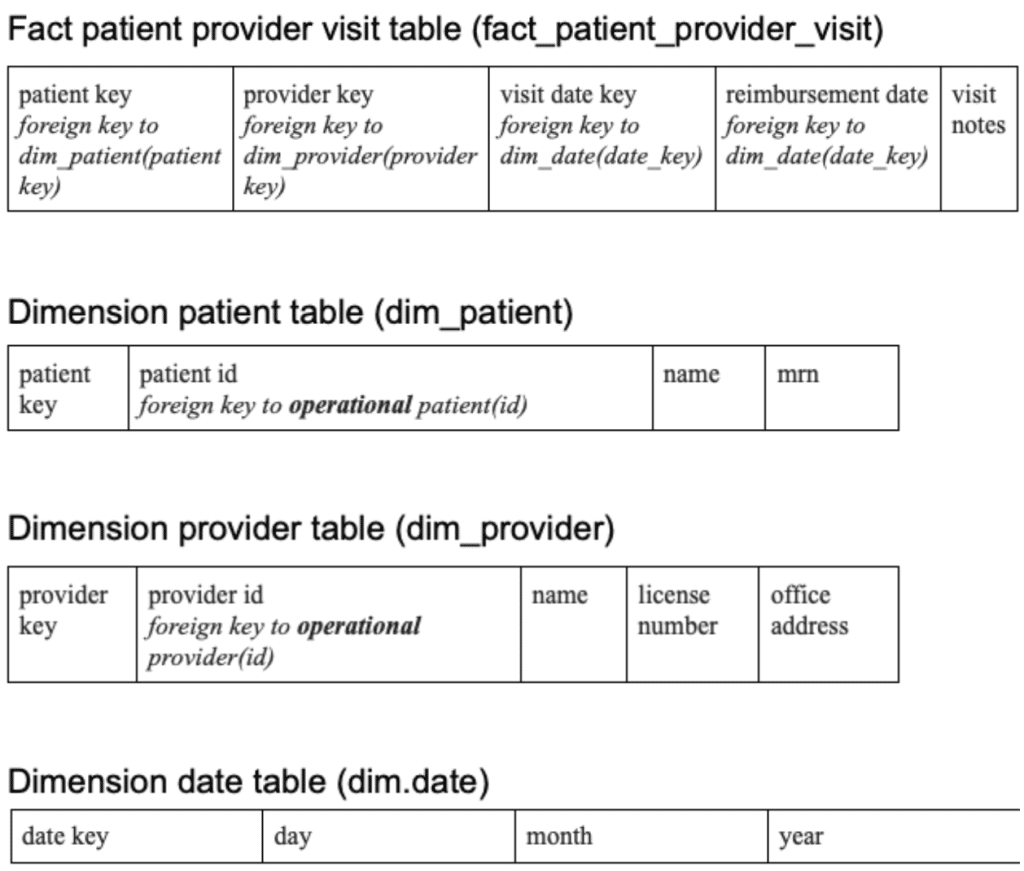
For our example, the dimensionality of the fact patient provider visit table is 4 because it contains 4 dimension key columns: patient key; provider key; visit date key; reimbursement date key. The range of values in the dimension key columns determine the granularity of the fact table.
Our example uses dimensions of Type 1 as its slowly changing dimension (SCD) type. This means that, when a slowly changing entity is updated in the operational database, the dimension record in our warehouse will be updated.
Up next
Slowly changing dimension (SCD) Type 2.
Bi-temporality.