Columnar Databases
ScaleUp! Community, previously we wrote about OLAP and data cubes, then a follow-up article with an example use of a data cube as well as a possible replacement. This article will dive deeper into columnar databases.
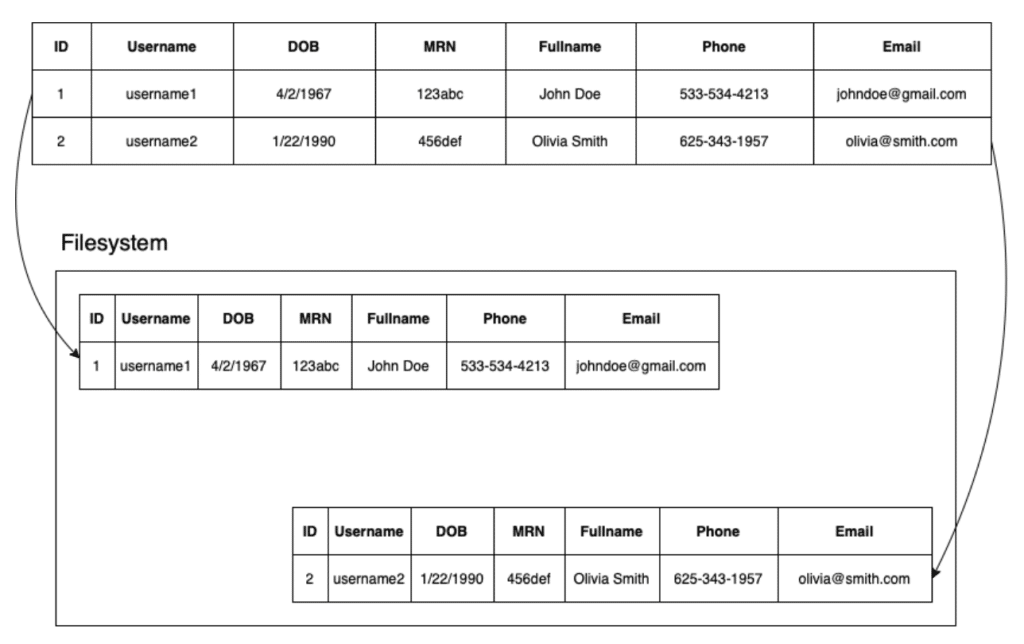
Row oriented database
A row oriented database stores data by row. The data for a given row will be located together on the file system. This is beneficial for OLTP use cases, where operations are typically performed on a single row or a range of rows.
Row 1 below would be stored together on the filesystem, row 2 below would be stored together on the filesystem, etc.
When user 1 logs in, the database reads their record (ID = 1) from the filesystem.
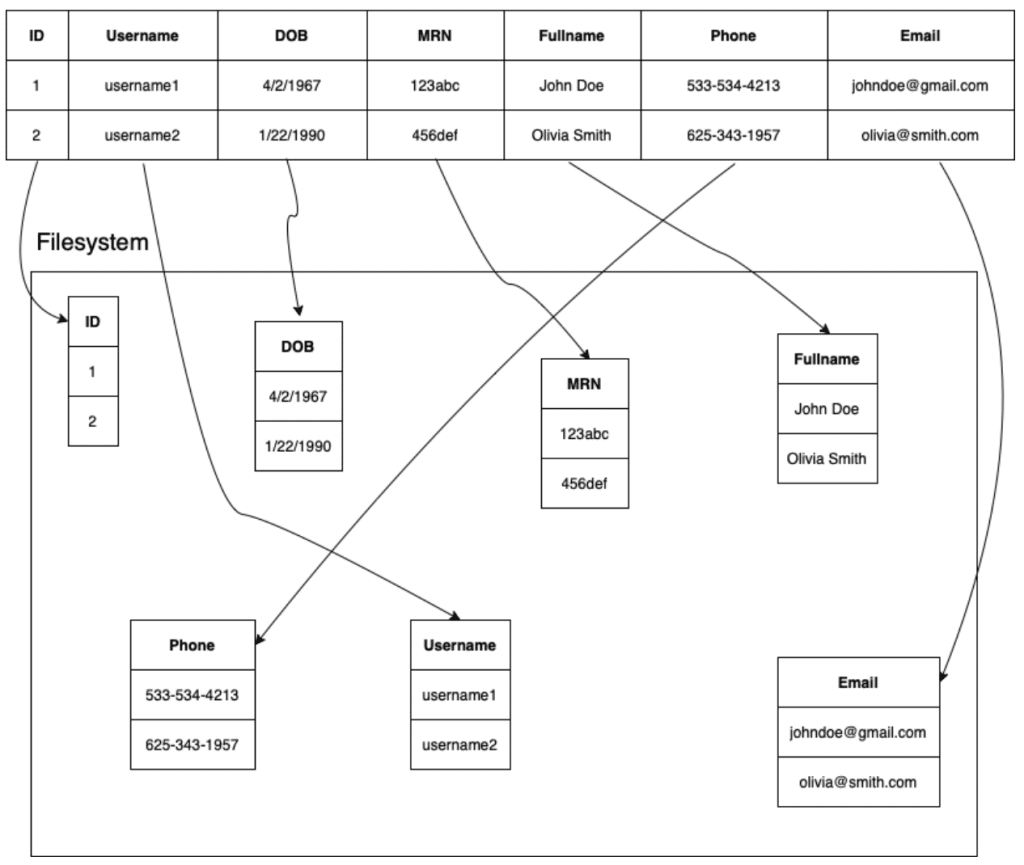
Column oriented database
A column oriented database stores data by column, not by row. The data for a given column will be located together on the file system. This is beneficial for OLAP (business intelligence) use cases, where operations are typically performed across many or all records but for a small number of attributes.
For example, for BI, you might want to see emergency department visits in the past quarter for all your users, stratified by age. For this query, you only need 2 attributes: ED visits and age, but you need these attributes for many rows. With a traditional database, this would require reading from storage the full data for each of these rows, where only a few attributes are actually needed. Since data is stored by row, this would require searching a large part of the filesystem, which is slow.
The DOB column below would be stored together on the filesystem; the ID column would be stored together on the filesystem; etc.
When analyst user 1 logs in, they will run their query, which will read from storage data from the DOB column and, from another table, the number of ED visits. The data for these columns is stored together so this area of the filesystem that must be searched is less than if the data was stored by row.